Guide
How to measure AI coding ROI (beyond the accept rate)
Seat counts and accept rates won't survive a budget review. How to measure AI coding ROI in three layers — cost, delivery, and practice — honestly.
At some point this year, someone with a budget will ask whether the AI coding spend is worth it. You will open the vendor dashboard, find a seat-utilization number and an acceptance rate, and realize neither answers the question. This guide is about what does: how to measure AI coding ROI in a way that survives a skeptical finance review — including which claims you can honestly make and which you can't.
The short version: there is no single number. There is a layered model — cost, delivery, practice — and the discipline to claim only what each layer supports. Most teams have the first layer, gesture at the second, and are missing the third entirely.
Why the obvious instruments mislead
The numbers you already have were designed to be easy to collect, not to measure ROI. Each fails in a specific way.
Seat utilization measures license consumption, not value. "92% of engineers used the tool this month" is the same kind of evidence as "92% of employees badged into the building." Utilization is worth tracking — paying for idle seats is pure waste — but a consumed license says nothing about whether the work got better, faster, or safer. High utilization with no downstream effect is the most expensive possible outcome, and seat dashboards cannot distinguish it from success.
Autocomplete accept rate doesn't apply to agentic work. Accept rate was a reasonable proxy when the tool was inline completion: suggestion appears, developer accepts or rejects, the ratio says something about suggestion quality. Agentic workflows broke that model. When a developer hands an agent a task and it plans, edits six files, runs the tests, and commits, there is no "suggestion" to accept — the unit of work is a session, not a keystroke. Teams still reporting accept rate for agent-heavy workflows are reporting a metric for a tool they no longer primarily use. And even where it applies, an accepted suggestion says nothing about whether it survived review, or got reverted on Thursday.
PR throughput moves for many reasons. PR count and cycle time feel closer to value, and they are — but as an AI-attribution instrument they are confounded to the point of uselessness. Throughput moves with headcount, ticket-slicing norms, on-call load, the one big refactor that ate March. AI also changes the shape of a PR, not just the count: bigger agent-written diffs can read as a slowdown, a flood of small machine-generated PRs as a speedup. If throughput went up 15% after rollout, you have a correlation and a dozen rival explanations. A board will accept that number. A good CFO won't.
Self-report surveys measure perception, not productivity. "Do you feel more productive with AI?" gets enthusiastic yeses, and those yeses are real data — about sentiment. The problem: perception and reality have now been measured against each other, and they diverge. Which brings us to the evidence.
What the public evidence actually says
Three findings are worth knowing cold before you put any ROI number in a deck, because whoever challenges your number may know them.
The METR randomized controlled trial (July 2025) is the sharpest result. METR ran an RCT with experienced open-source developers working on large, mature repositories they knew well. With AI tools allowed, developers took 19% longer to complete tasks — while estimating, afterward, that AI had made them 20% faster. A 39-point gap between perceived and measured productivity, in a controlled setting (study and methodology here).
Scope it honestly, because the caveats cut both ways. This was a small group of expert developers on codebases they had years of context on — close to the worst case for AI assistance. It does not prove AI slows everyone down. What it does prove is narrower and more damaging to lazy measurement: developer self-assessment of AI productivity can be wrong not just in magnitude but in sign. If your ROI case rests on a survey, METR is the rebuttal someone will hand you.
Google's DORA 2024 report found that as AI adoption increased, software delivery stability decreased — an estimated −7.2% to delivery stability (RedMonk's summary of the findings). This is correlational survey data, not a controlled experiment, so treat it as a caution rather than a verdict. The plausible mechanism is the one you'd guess: AI makes it easy to produce large batches of code, and large batches have been associated with worse delivery outcomes in every DORA report since the beginning. Faster code production is not faster software delivery if it arrives as bigger, riskier changes.
The LeadDev Engineering Leadership Report (March 2025) surveyed 617 engineering leaders; only 6% reported significant productivity boosts from AI tools. So when you report results honestly and they look unspectacular, you are not behind the industry — you are describing it.
None of this says the spend is wasted. It says the gains are not automatic, not evenly distributed, and not measurable by perception. Which is an argument for better instrumentation, not for giving up.
A practical layered measurement model
The most useful public framing here is the DX AI Measurement Framework, which organizes measurement into utilization, impact, and cost dimensions. We use a similar three-layer model, with one addition the standard frameworks leave implicit: a layer for how people use the tools, not just whether and to what effect.
Layer 1 — cost and utilization. What you spend and who actually uses it: seats, token/API spend, active users, sessions per engineer per week. This layer is cheap to build and you should build it first, because it catches the unambiguous waste — paid seats nobody touches, spend concentrated on three people. Just keep it in its lane: this layer measures inputs.
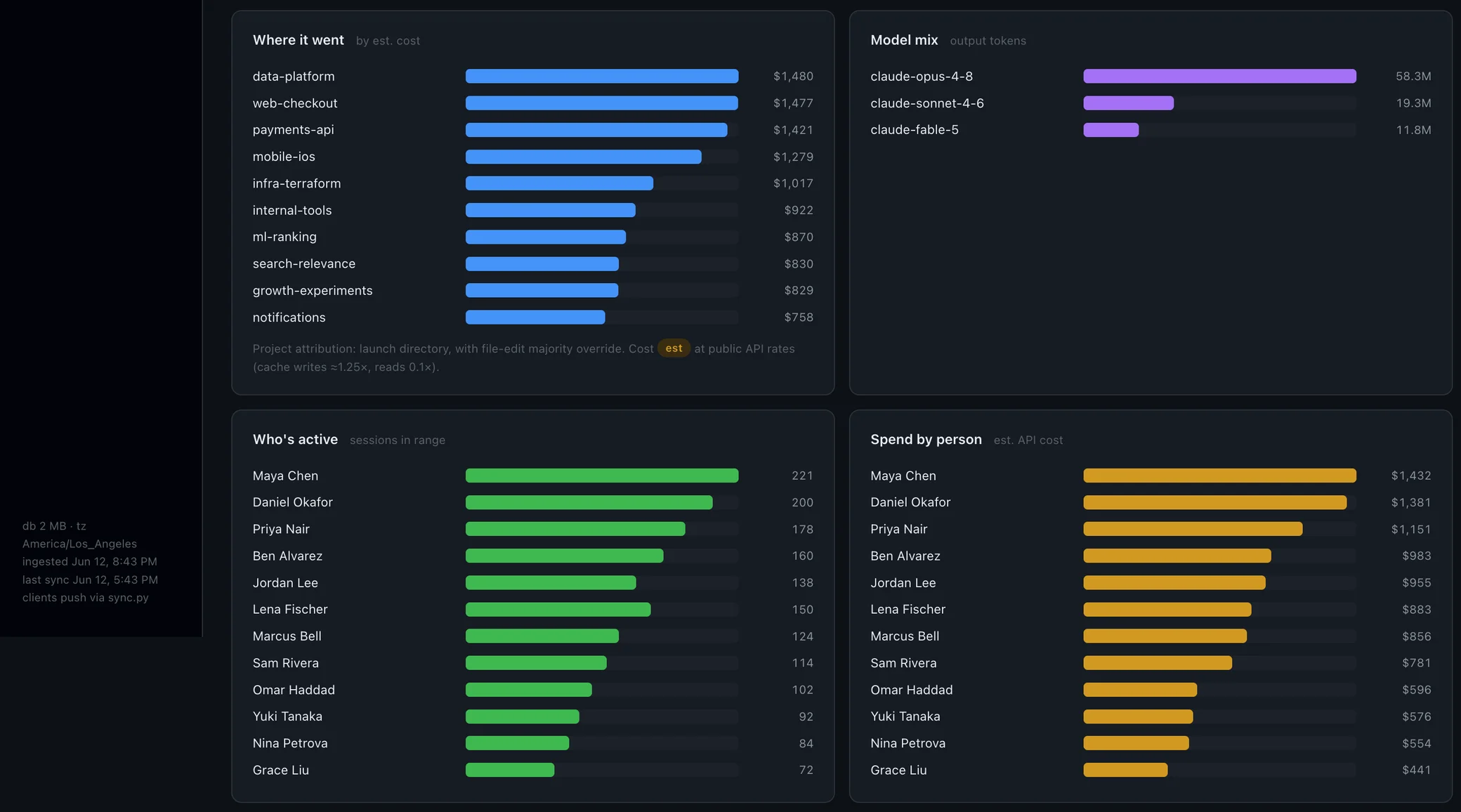
Layer 2 — delivery. Your existing engineering metrics — cycle time, review time, change failure rate, rework — watched for movement after rollout. This is where ROI ultimately has to show up. The honest difficulty is attribution, for all the confounding reasons above; cohort comparisons and staged rollouts help, but at realistic team sizes this layer mostly supports "directionally consistent with impact," not proof. We cover which of these metrics are worth the trouble in our guide to developer productivity metrics.
Layer 3 — practice. This is the layer that's usually missing, and it answers the question the other two can't: is the team actually getting good at this? Layer 1 tells you people opened the tool. Layer 3 tells you what they did inside it, drawn from real session data: who plans before coding, who delegates to subagents, who manages context deliberately versus pasting snippets into a chat box. These are concrete, observable behaviors, and they are where the variance lives. Two engineers with identical seat utilization can be having completely different experiences — one running a disciplined agent workflow, one fighting a chatbot for an hour — and layers 1 and 2 render them identical.
The practice layer is also the only one you can directly act on. You can't manage cycle time by staring at it; you can teach a specific engineer a specific practice next week. This is the layer Accrete instruments: parsing real Claude Code sessions into a per-person, per-practice adoption matrix, so the gap between having the tool and being skilled with it becomes visible. That gap is its own topic — see adoption versus proficiency.
What you can honestly claim at each layer
The model only works if you respect each layer's limits. As a rule: claim observations freely, claim causation almost never.
- Cost layer: "We spend $X per engineer per month; 84% are weekly-active; spend per active user fell 30% after we cut idle seats." Fully defensible. This is accounting.
- Delivery layer: "Cycle time improved 12% over the two quarters following rollout, with no major confounds we could identify." Defensible as correlation, honestly labeled. Not defensible: "AI made us 12% faster." You don't have a counterfactual, and METR shows how wrong the intuition can be.
- Practice layer: "Nine of fourteen engineers now plan before coding in agent sessions, up from three last quarter; the practices our strongest people use are spreading." Fully defensible — these are observed behaviors in session data, not estimates. What this layer doesn't claim by itself is dollar impact; it claims the leading indicator that makes dollar impact plausible.
Stacked together, the three layers make a case no single metric can: we know what it costs, delivery is moving the right direction, and we can show — with evidence — that the team is measurably more skilled than last quarter. That's a position you can defend in a budget review without flinching.
Common mistakes
- Reporting utilization as ROI. "Adoption is at 90%" answers "did they install it," not "was it worth it." It's the most common slide in AI rollout decks and the easiest to puncture.
- Letting the vendor's dashboard define your metrics. Vendor dashboards report what makes the vendor look good — seats, suggestions, accepted lines. Your measurement model should be tool-agnostic, or it dies when your stack changes.
- Anchoring on self-report. Run sentiment surveys — morale matters. Just never let perceived speedup anchor the ROI number; METR's 39-point perception gap is the standing counterexample.
- Measuring code production instead of delivery. Lines generated and PRs opened are output, not outcomes. DORA 2024's stability finding is what it looks like when production accelerates and delivery quality pays for it.
- Skipping the practice layer. Without it, every disappointing delivery number is unexplainable. Is the tool weak, or are people using it badly? Session-level practice data is the only way to tell those apart — and the only version of this problem you can coach your way out of.
- Expecting one number. Anyone offering a single "AI ROI score" is selling something. Three layers, scoped claims, trends over snapshots.
Where to start
Stand up the cost layer this week — it's mostly spreadsheet work. Pick two delivery metrics you already trust and mark the rollout date. Then instrument the practice layer, because it's the one that tells you what to do — the full approach is in measuring AI coding impact, and this guide is part of our broader guides series on running an evidence-based AI rollout.
We're pre-launch: no public benchmarks of our own yet, which is exactly why we hold the public evidence to the standard above. If you want the practice layer on your own team's sessions, join the early access list — or become a design partner and shape the practice catalog with us.