Guide
Developer Productivity Metrics in the AI Era: What DORA and SPACE Can't See
DORA, SPACE, and DX Core 4 measure delivery outcomes. AI moved the variance into the working session. What the frameworks miss, and what to add.
If you run an engineering org, you already have a measurement stack. Probably DORA metrics on the delivery pipeline, maybe a SPACE-informed survey, possibly the DX Core 4 if you've modernized recently. These are good frameworks, built by serious people, and nothing in this guide tells you to throw them out.
Here's what changed: AI coding moved the most interesting variance in your org from the delivery pipeline into the working session — and the working session is exactly the place none of these frameworks look. Not because they're flawed. Because they were deliberately designed not to.
This guide walks through what each framework actually measures, why AI created a blind spot underneath all of them, and what a session-level practice layer adds without replacing anything.
The frameworks, honestly
Before arguing about a gap, it's worth being precise about what each framework is good at. These are not straw men.
DORA: delivery outcomes
DORA's four keys — deployment frequency, lead time for changes, change failure rate, time to restore — measure the health of your delivery pipeline. They're outcome metrics with two decades of research behind them, they resist gaming better than most alternatives, and they correlate with organizational performance. If your lead time is three weeks, DORA will tell you, and that's worth knowing regardless of what your engineers do with AI.
What DORA is for: telling you whether the system that turns commits into running software is healthy. What it is not for: telling you anything about how the commits got written.
SPACE: the corrective to single-number thinking
SPACE exists largely as a correction — productivity is not one number, and any single metric will be gamed or misread. Its five dimensions (satisfaction and well-being, performance, activity, communication and collaboration, efficiency and flow) force you to look at developer experience and team dynamics alongside output. The satisfaction dimension in particular catches problems — burnout, friction, tooling pain — that pure throughput metrics hide until people quit.
SPACE is a framework for thinking, more than a fixed metric set. Used well, it stops you from doing the dumbest version of measurement.
DX Core 4: the operational synthesis
The DX Core 4 unifies DORA and SPACE into four dimensions a leadership team can actually run on: speed, effectiveness, quality, and business impact. It's pragmatic, it's benchmarkable across companies, and DX has been clear-eyed about the failure modes of productivity measurement in a way that's earned trust. Notably, DX is explicit that these metrics are for organizational and team-level insight — not for evaluating individual developers. That's a principled position, and for performance management it's the right one.
DX has also published a thoughtful framework for measuring AI code assistants and agents — utilization, impact, and cost of AI tooling. If you're building an AI measurement program, read it. We build on this framing rather than against it.
So: three credible frameworks, each answering real questions. Now the gap.
What AI changed
Pre-AI, the big productivity levers were mostly organizational: batch size, review latency, deploy automation, team topology. Individual technique mattered, but it was roughly normally distributed and slow-moving — two senior engineers on the same team worked in broadly similar ways, and the way they worked changed over years, not quarters.
AI coding broke that assumption. Two engineers can now sit on the same team, with the same license, contributing identical-looking DORA outcomes — same merge cadence, same review pipeline, similar change failure rate — while working in radically different ways. One plans before delegating, breaks work into reviewable chunks, manages the agent's context deliberately, and verifies output against the spec. The other prompts, accepts, and pushes. From the pipeline's vantage point this quarter, they're indistinguishable. Over the next four quarters, they won't be.
This is the structural problem. The interesting variance moved upstream of everything the frameworks instrument, into the session itself. And the frameworks are deliberately org-level — DX explicitly avoids individual-level measurement, DORA aggregates by service or team, SPACE warns against individual surveillance. Those design choices were correct for what the frameworks do. They also mean that when the variance moved into individual working sessions, the entire measurement stack agreed, on principle, not to look there.
The DORA 2024 paradox is the tell
You can see the blind spot in DORA's own data. The 2024 DORA report found that increased AI adoption correlated with a decrease in delivery stability — down 7.2% — even as developers reported individual benefits. RedMonk's analysis of the 2024 report is a good read on this: the tooling is being adopted enthusiastically, and the delivery outcomes got worse, not better.
Sit with what that result actually demonstrates about measurement. The outcome metrics did their job — they registered that something is happening. AI adoption is real, and it's perturbing the delivery system. But the outcome layer cannot tell you what to change. Is stability dropping because engineers ship larger, less-reviewed batches? Because generated code passes review it shouldn't? Because nobody plans before pointing an agent at the codebase? Because the strongest engineers got faster and the weakest got faster at producing problems? The DORA number is identical in all four worlds, and the four worlds need four different interventions.
That's the definition of a lagging indicator without a leading layer beneath it. The instrument detects the symptom and is structurally silent on the cause — because the cause lives inside sessions, and nothing in the stack observes sessions.
The missing layer: practice signals
The leading indicators for AI-era engineering quality are practice signals: concrete, detectable behaviors inside the working session. Did the engineer plan before coding? Delegate scoped work to subagents instead of one sprawling thread? Use saved skills and commands rather than re-prompting from scratch? Track tasks? Manage memory and context deliberately? Commit work in coherent units?
These aren't survey answers or vibes. They're observable in session transcripts, the way deploy frequency is observable in your CI logs. And they sit causally upstream of the outcomes DORA measures: an engineer who plans, decomposes, and verifies produces smaller, better-reviewed changes, which is the mechanism by which change failure rate stays low as AI throughput rises. When the 2024 stability number drops, the practice layer is where the explanation lives.
This is what we build at Accrete: ingest real Claude Code sessions, classify the practice signals in each one, and surface a per-person, per-practice adoption matrix — who has adopted which practices, who hasn't, where the team plateaus. A practice counts as adopted per session it appears in; volume is tracked separately, because adoption and proficiency are different things and conflating them is how seat-count dashboards lie to you.
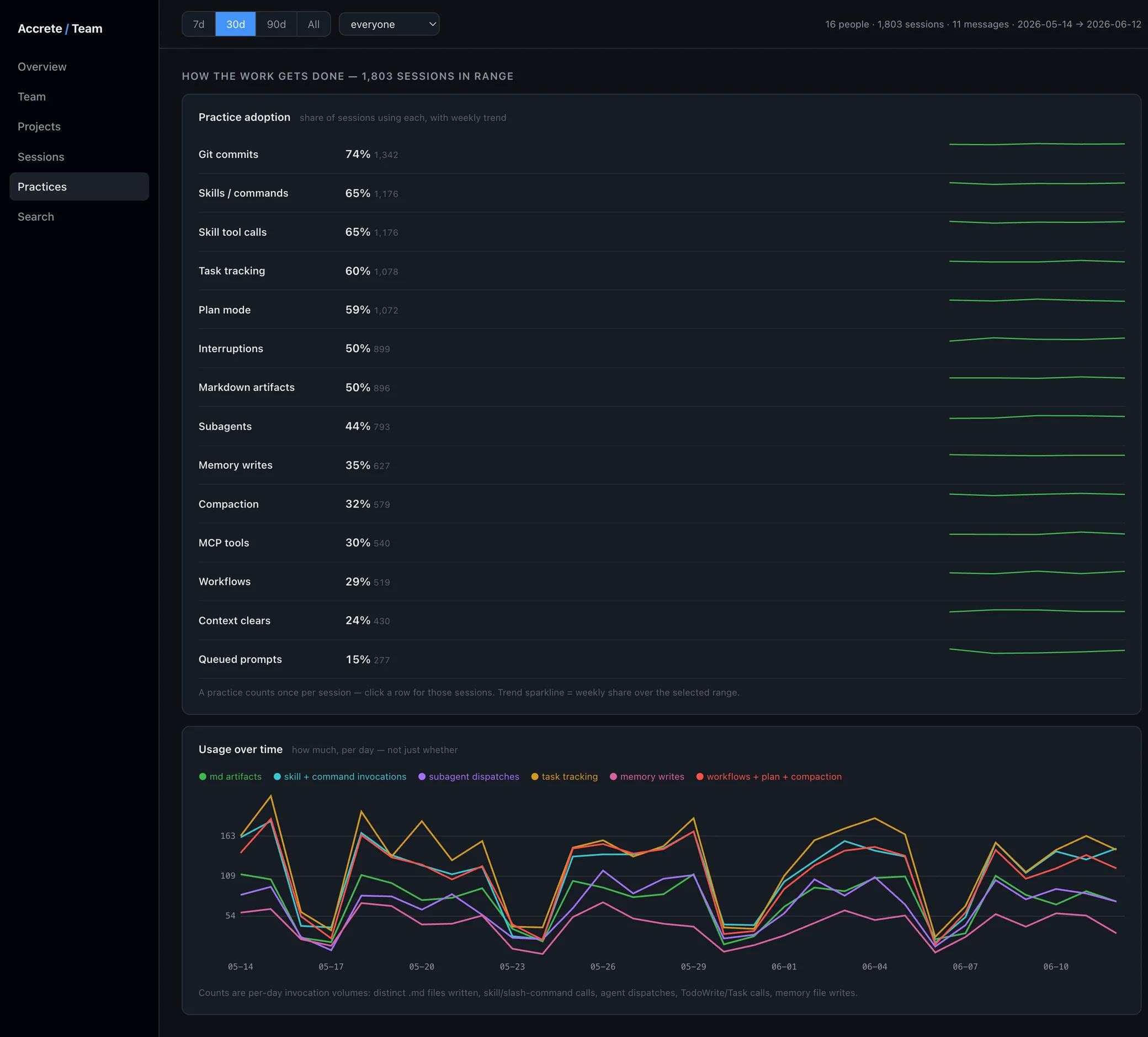
The caveats, plainly: practice signals are leading indicators, not proof of outcomes — a planned session can still produce a bad change. We observe agent sessions, not every AI touchpoint in your stack. And we're pre-launch, so we have no published benchmarks correlating practice adoption with DORA movement yet; that correlation is the thesis, and the honest status is "this is what the instrument is built to test."
How the layers compose
The wrong conclusion from all this is "replace DORA with session metrics." Don't. Outcome metrics are how you know whether anything is actually improving; without them, practice data is unanchored. The right move is to add the practice layer under the outcome layer:
- DX Core 4 / DORA on top — org-level outcomes, the scoreboard. Are speed, quality, stability, and business impact moving?
- Practice signals underneath — session-level behaviors, the explanation and the lever. When the scoreboard moves (or doesn't), this layer tells you which behaviors changed, for whom, and what to coach next.
The layers also resolve the individual-measurement tension cleanly. DX is right that outcome metrics shouldn't be used to rank individuals — outcomes are too confounded by project mix and luck. Practice signals are different in kind: they're coaching data, not performance-review data. "You haven't tried plan mode; here's a session from a teammate who uses it well" is a coaching conversation, not a stack ranking. The point of seeing individual practice is to spread what the strongest people do, which we cover in depth in measuring AI coding impact.
Which questions each layer answers
A practical way to keep the stack straight — match the question to the layer:
| Question | Layer |
|---|---|
| Is our delivery system healthy? | DORA |
| Are developers satisfied, and is the experience sustainable? | SPACE |
| How does our org compare, and is the investment paying off overall? | DX Core 4 |
| Is the AI rollout perturbing delivery outcomes? | DORA / Core 4 trends |
| Why did stability move when AI adoption rose? | Practice signals |
| Who on the team has actually adopted effective AI practices? | Practice signals |
| What do our strongest engineers do differently in sessions? | Practice signals |
| What specifically do we coach next quarter? | Practice signals |
If a question is about whether you're winning, look up the stack. If it's about what to change, look down. The expensive failure mode is asking a "what do we change" question of an outcome metric — that's how orgs respond to a stability dip with a mandate ("more careful with AI, everyone") instead of an intervention.
For the budget conversation — how practice data fits with cost and outcome layers in an actual investment case — see our guide to measuring AI coding ROI. The rest of our guides cover the adjacent questions.
Where this goes
DORA, SPACE, and the Core 4 took a decade-plus to mature, and they earned their place. The session-level practice layer is younger and less proven — we'd rather say that than oversell it. But the 2024 paradox isn't going to resolve itself from the outcome layer, because the outcome layer can't see the thing that's varying.
If you want the instrument that looks where the variance went: join the early access list. If you want to shape it — which practices get measured, what the adoption matrix should show your org — work directly with the founder as a design partner, with early pricing.