Essay
Adoption Is Not Proficiency
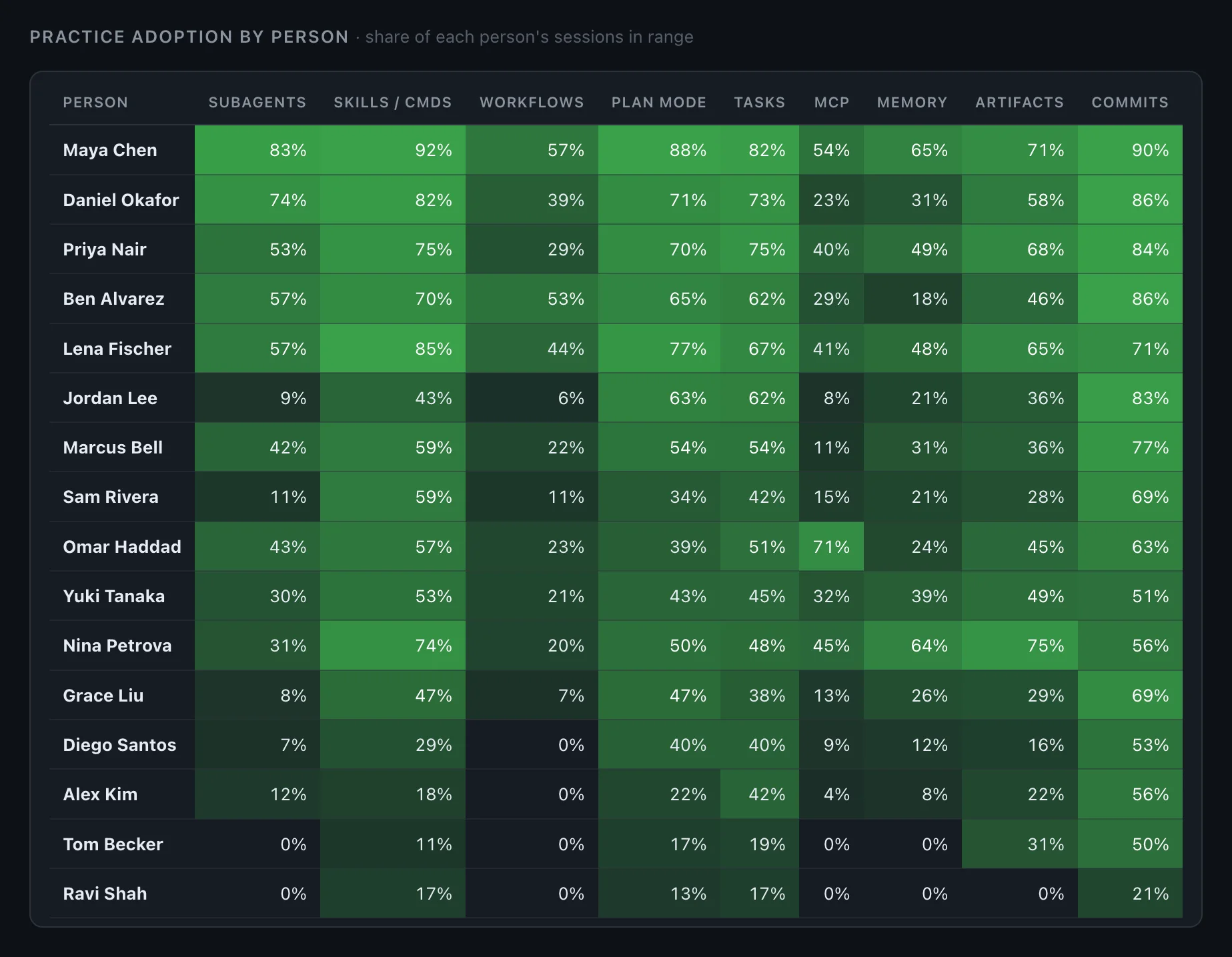
Every AI-coding metric you have measures adoption, not skill. The 4x gap between your best and median users is invisible in all of them.
Every dashboard your AI-coding vendor gives you measures the same thing: whether people are using the tool. Seats active. Sessions run. Tokens consumed. Percentage of code AI-written. These are adoption metrics, and adoption metrics answer exactly one question — did the rollout happen?
Then something quiet and unjustified occurs. The adoption number gets reported upward as if it were a skill number. "82% weekly active" becomes "the team is good with AI now." Nobody decided this consciously. It's just that adoption is the only number anyone has, so it gets pressed into a job it cannot do.
This is the central measurement error in AI-assisted engineering right now, and it matters because the distance between adoption and proficiency — the AI coding adoption vs proficiency gap — is where essentially all of the return lives.
The spread is the story
Hand the same tool, the same model, and the same access to a hundred engineers and you do not get a hundred similar outcomes. You get an enormous spread.
OpenAI's 2025 analysis of enterprise usage found roughly a 4x productivity gap between power users and typical users — people with identical access to identical tools. The usual caveats apply: it's a vendor's analysis of its own customers, and "productivity" in usage-data studies is always a proxy. But the direction matches what anyone who has read a large pile of agent transcripts already knows. Some people get the agent to plan, verify, and ship coherent work. Others paste an error message, accept whatever comes back, and paste the next error message. Same seat license. Same line on your adoption chart.
That spread is invisible in every metric you currently collect. Seats-active treats the 4x engineer and the flailing one identically. Tokens-burned actually inverts the signal — the flailing engineer often burns more, re-prompting their way around problems a skilled user would have headed off with a plan. Percentage-of-code-AI-written tells you who delegates typing, not who delegates well.
"Just ask people how it's going" doesn't work either
The obvious fallback is self-report: survey the team, ask who feels faster. The best evidence we have says self-perception is not a usable instrument here.
In 2025, METR ran a randomized controlled trial with experienced open-source developers working on large repositories they knew deeply. With AI assistance, they were 19% slower on average — while estimating they had been sped up by about 20%. A 39-point gap between perceived and measured effect, in the unflattering direction.
Be careful with this result; it gets over-quoted. The sample was small (16 developers), the setting specific — experts on mature codebases they'd contributed to for years, using early-2025 tools — and METR themselves caution against generalizing to "AI doesn't help anyone." It plausibly helps a great deal in other settings: unfamiliar code, greenfield work, stronger tooling, more practiced users.
What the study does establish is narrower and more damning for measurement: engineers' felt experience of AI speedup is unreliable, even among experts. If experienced developers can be 19% slower while certain they're 20% faster, then your team's survey responses, your skip-levels' enthusiasm, and the confident anecdotes in Slack are not data about proficiency. They are data about vibes.
So self-report can't measure the gap, and adoption metrics can't see it. Which leaves leaders exactly where the LeadDev survey of 617 engineering leaders (March 2025) found them: only 6% reported significant productivity gains from AI tools. Read that next to the near-universal adoption numbers the same industry reports, and the conclusion is hard to avoid. Adoption is roughly solved. Proficiency is barely started. And the people accountable for the difference can't see it — a problem we go deeper on in measuring AI coding ROI.
Why we keep measuring the wrong thing
Adoption metrics persist because they're cheap, not because anyone believes in them. They fall out of license servers and API logs for free. They're procurement-shaped: they justify the spend that already happened. And they go up and to the right during a rollout, which makes them pleasant to present.
Proficiency is harder because it lives somewhere nobody looks: inside the sessions. Not in the diff that came out the other end — in the actual back-and-forth between engineer and agent. Whether there was a plan before there were edits. Whether the engineer caught the agent going sideways at minute three or minute forty. Those transcripts mostly get discarded (Claude Code purges them after about 30 days), and almost no organization reads them before they vanish.
Proficiency is observable
Here is the constructive claim, and the one we'd stake the company on: skill with coding agents is not a vague aura. It decomposes into concrete, detectable session behaviors. When you read transcripts from strong operators side-by-side with median ones, the same differences keep showing up:
- Planning before edits. Strong users make the agent produce and agree on a plan before code changes start. Median users start typing and steer by collision.
- Delegating research to subagents. Strong users fan exploratory work out to parallel agents and keep the main thread clean. Median users let one context window silt up until the agent forgets the task.
- Maintaining context deliberately. Memory files, task lists, durable project notes the agent can read — versus re-explaining the codebase from scratch every session.
- Inspecting and steering, not accepting. Strong users read the diff, interrupt early, redirect with specifics. The defining median behavior is the blind "looks good, continue."
- Saved, repeatable workflows. Skills and reusable commands that encode something that worked once — versus re-improvising the same prompt forever.
None of these is a talent. Each is a habit, with a name, that shows up as a detectable signal in session data — which means each one can be taught. That's the difference between treating your 4x engineers as a lottery outcome and treating them as a curriculum. We catalog these signals and how we detect them in our guides, and the detection mechanics are laid out in how it works.
The honest limitation, stated plainly: observing these behaviors measures practice, not outcomes directly. A session with a plan can still produce a bad PR. We think practice signals are the best available leading indicator — they're concrete, comparable, and coachable, which vibes and seat counts are not — but anyone selling you a single number for "AI productivity" is selling you the old mistake with new packaging. We're pre-launch and have no published benchmarks yet; as our dataset grows, we'll publish what we find in our research, caveats included.
What to do Monday
You don't need a vendor to start; you need a different question. Not "is the team using AI?" — that's answered. Ask "what do our best users actually do?"
- Read real sessions. Pull transcripts from five engineers this week, before the 30-day purge eats them. Read the prompts, not just the output. It will be the most informative hour you spend this quarter.
- Find your 4x people. You likely already suspect who they are. Verify it in their sessions, not their reputation.
- Name what they do. Turn what you see into a short list of named practices — planning, delegation, context discipline, inspection. A behavior with a name can be asked for, taught, and checked. An aura can't.
- Track adoption of practices, not tools. Who has picked up which practice is a question with an answer. That's the matrix worth managing — and it's how teams discover the practices worth spreading instead of guessing.
This is the work Accrete exists to do continuously: capture the sessions durably, detect the practice signals, and show you the per-person gap so coaching runs on evidence. If that's the problem on your desk, join the early access list — or become a design partner and shape the practice catalog with us while it's still early.