Use case
Measure AI coding impact — with session evidence, not seat counts
Seat counts and acceptance rates can't tell you if AI coding is working. Measure practice adoption and skill from your team's real sessions.
You're paying real money for AI coding licenses. The vendor dashboard says adoption is high — most of the team active every week. One staff engineer swears it's the biggest productivity change of her career. Another quietly calls it a code-review tax. And somewhere on next quarter's agenda is a CFO, a CEO, or a board slide that asks: is this investment working?
Right now, you don't have an instrument that answers that. You have an instrument that says people are using the tool. Nothing tells you whether anyone is getting better at it.
Why the standard instruments fail
Each of the usual measures answers a different question than the one you're being asked.
- Seat and usage counts measure license consumption. They confirm the tool is open, not that it's used well. High usage by someone working ineffectively is a cost, not a win.
- Acceptance-rate metrics were built for autocomplete. Agentic work — planning, delegating to subagents, iterating over a session — isn't accepted line by line, so acceptance rate mostly measures the part of AI coding that matters least now.
- DORA-style throughput moves for many reasons: headcount, project mix, a re-org, a quiet quarter. Attributing a deploy-frequency bump to the AI rollout is the kind of claim a skeptical CFO takes apart in one question.
- Surveys measure sentiment. The engineers who love the tool are not necessarily the ones who are good with it, and self-reported productivity is famously unreliable.
None of these are bad metrics. They're just not measuring AI coding skill — which lives inside sessions, where none of them look.
What Accrete measures instead
Accrete observes your team's real Claude Code sessions and detects concrete practice signals in each one: planning before coding, delegating to subagents, using skills and saved commands, task tracking, memory and context management, committing work. Not survey answers — detectable behaviors in actual transcripts. (The full mechanics, including what syncs and what doesn't, are on how it works.)
From that you get a per-person, per-practice adoption matrix and its trend over time:
- Who has adopted which practices — and who hasn't, by name.
- How it's trending — whether the rollout is still compounding or has stalled.
- Where the team plateaus — the practices nobody picks up without a push.
- What the strongest sessions look like — drill into them, see the difference, and spread it. That last part is the point; measurement exists to feed coaching your team.
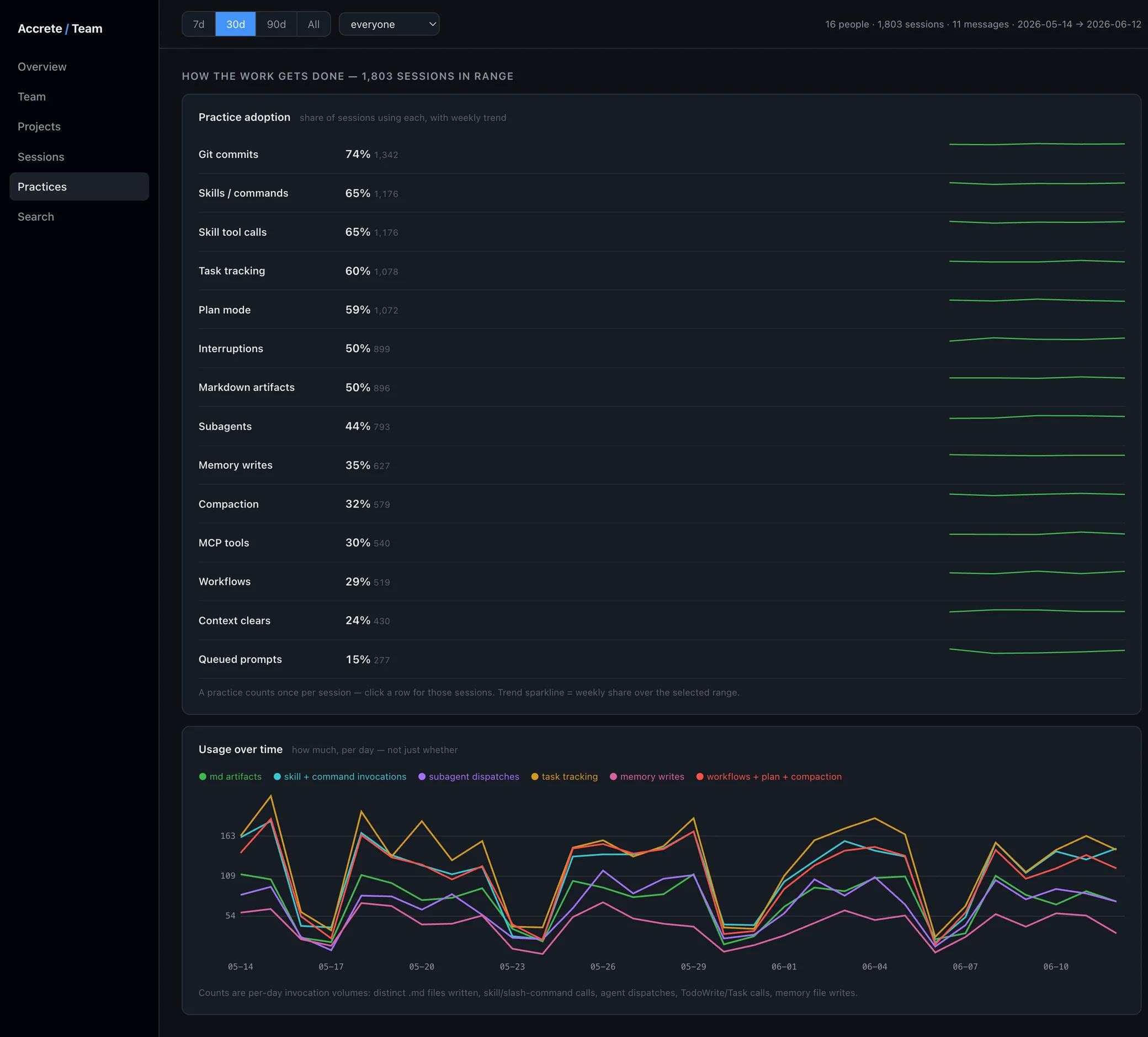
Adoption is not proficiency
This is the distinction the seat-count dashboard erases, so we keep it explicit in the data model.
A practice counts as adopted per session it appears in. Volume of use is tracked separately. An engineer who tried plan mode once in March and an engineer who plans every substantial piece of work both show up as "users" in a usage chart. They are not the same engineer, and your investment case depends on knowing the difference.
Everyone on your team has a license. That fact contains no information. The measurable thing is the gap between holding the tool and working skillfully with it — how wide it is, for whom, and whether it's closing. That gap is what you're actually buying when you fund an AI coding rollout, and it's the number nobody is currently giving you.
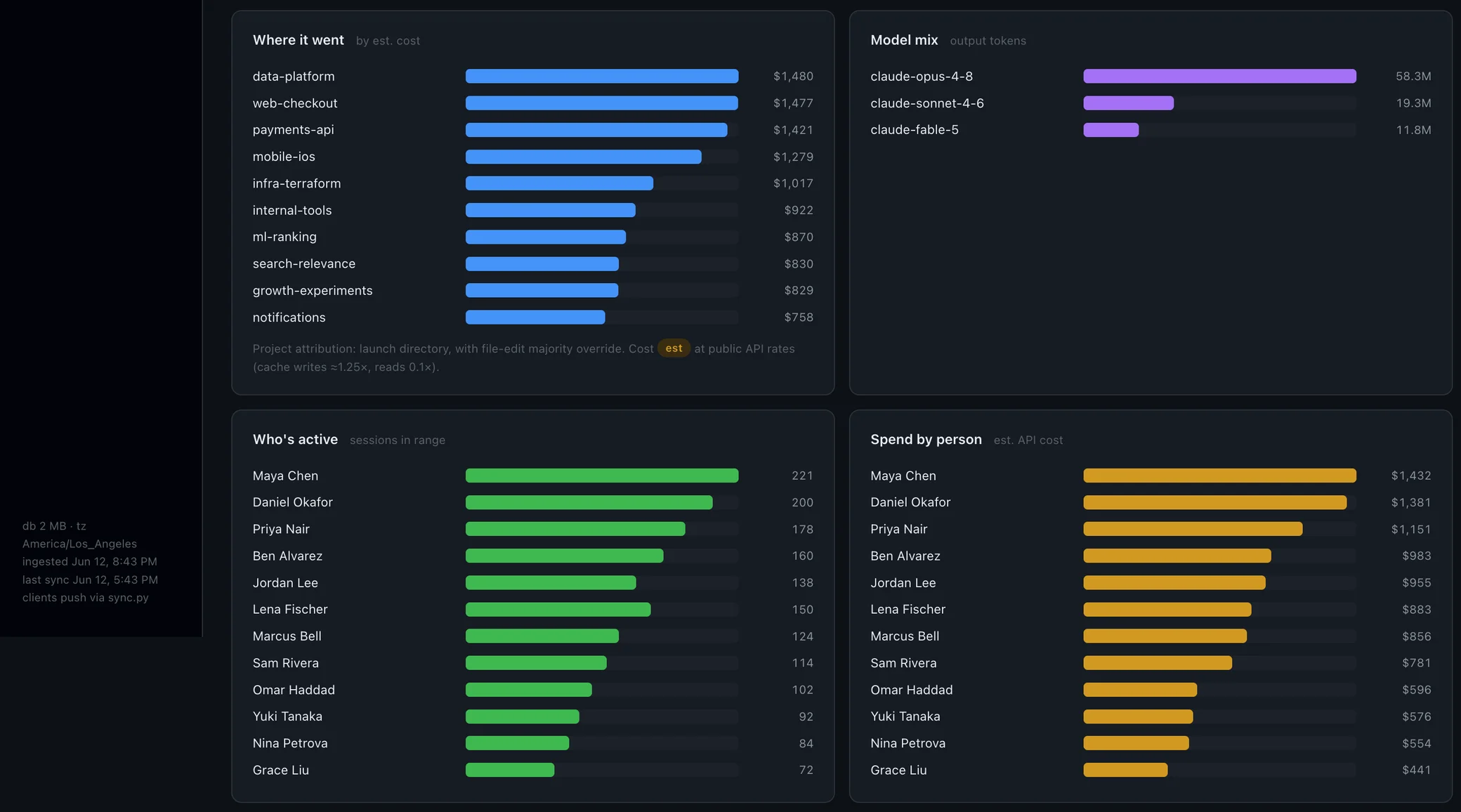
What you'd actually be able to say in the QBR
The honest test of a measurement system is whether it survives a hostile room. With practice-level session data, you can stand behind sentences like these — illustrations of the kind of claim the data supports, not results we're quoting:
- "Plan-mode adoption went from a third of the team to most of it this quarter. Here's the trend, and here are the sessions behind it."
- "Our strongest sessions share three practices. Six engineers use none of them yet — that's the coaching plan for Q3."
- "We plateaued on subagent delegation in April. Here's the intervention, and here's the date we'll know if it worked."
Each one is a claim about observed behavior, traceable to real sessions — not a sentiment score, not a throughput number you'd have to defend against confounders.
What this doesn't do: it won't attribute revenue to AI coding, and it observes agent sessions, not every AI touchpoint in your stack. Practice data is one layer of an investment case, not the whole thing — our guide to measuring AI coding ROI covers how it fits with the cost and outcome layers. And we're pre-launch: no public customers or benchmarks yet. We'd rather say that than imply otherwise.
Get the instrument before the next board slide
Join the early access list. Or work directly with the founder as a design partner — shape the practice catalog around what your team needs to measure, with early pricing.