Guide
Coaching Engineers on AI Tools: A Practical Guide
A practical guide to coaching engineers on AI tools: what to coach, how to review sessions without surveillance, and how to start without tooling.
Your team has the licenses. Some people are doing remarkable work with agents; most are not. The gap is not small: OpenAI's 2025 enterprise data put power users at roughly 4x the usage of typical users on the same tools. Inside an engineering team, that gap is not a curiosity — it's the difference between the people whose throughput actually changed and the people who renamed their autocomplete.
This guide is about closing that gap through coaching: what to coach, how to run the sessions so nobody feels watched, and how to start this week with nothing but a calendar invite. It assumes you're an EM or staff+ engineer who owns enablement and is done hoping the gap closes itself. It's one of several guides we've written on running this well.
Why coaching, not training
The default move is training: book a workshop, demo the tools, share a prompt doc. Do it — it's cheap and it sets a floor. But be honest about what it produces. A workshop transfers awareness. People leave knowing that plan mode exists, that subagents exist, that context windows degrade. Three weeks later, under deadline, almost nobody's actual Tuesday-afternoon behavior has changed.
Skill doesn't transfer through awareness. It transfers through observed reps and feedback — someone watches you do the work, points at a specific moment, and says "here, do this differently." Every discipline that takes skill seriously runs on this loop. Sales teams record calls and review them together; that practice, more than any pitch deck, is how a B-player learns what an A-player does on the third objection. Sports teams review film. Surgeons review recordings. The mechanism is identical everywhere: the rep is captured, the rep is reviewed, the feedback is specific.
Engineering has never done this for AI work. The session — where the skill is actually exercised — happens privately in a terminal. We review the output (the PR) obsessively and the process never. So our best practitioners' technique stays trapped in their own sessions, and everyone else reinvents it badly or not at all.
Coaching, then, means three commitments: you will look at real sessions, you will give feedback on specific moments in them, and you will do it repeatedly. Everything below is in service of those three.
What to coach: a practice curriculum
"Get better with AI" is uncoachable. Coach named behaviors. Here are six that separate strong agent practitioners from the rest, each with what it looks like and the signal that it's missing. (Our AI coding best practices guide goes deeper on each.)
Planning before agentic edits
What it looks like: Before letting an agent touch files on anything non-trivial, the engineer gets a plan — plan mode, or simply "propose an approach before editing." They read it, correct it, then release the agent. The expensive disagreement happens at the plan stage, where it costs a paragraph, not at the diff stage, where it costs a rewrite.
Signal it's missing: Large diffs rejected wholesale. Sessions where the agent builds the wrong thing competently and the human discovers it twenty minutes in. "It went off and did something crazy" is almost always a planning failure, not a model failure.
Scoping prompts
What it looks like: Prompts that read like good ticket descriptions: the task, the relevant files, the constraints, what "done" means. Not novels — boundaries. "Add retry logic to the sync client, in sync.py only, follow the existing error-handling pattern, don't touch the schema."
Signal it's missing: One-line prompts followed by long correction chains. Count the turns: if a task routinely takes eight back-and-forths, the first message was underspecified and the engineer is paying for it in installments.
Delegating to subagents
What it looks like: Research, codebase exploration, and parallelizable work get farmed out to subagents, keeping the main session's context clean for the actual task. The engineer thinks like a lead: what can I hand off so my own working memory stays on the hard part?
Signal it's missing: Monolithic sessions that do everything serially — search, read, plan, edit, test — until the context fills with file dumps and the agent's quality visibly degrades in the back half.
Context hygiene
What it looks like: Memory files that carry conventions and decisions between sessions, so the agent isn't re-taught the codebase every morning. Task lists for multi-step work, so nothing falls out of a long session. And the judgment call that distinguishes practitioners: knowing when a session is polluted — full of dead ends and stale assumptions — and starting clean rather than arguing with it.
Signal it's missing: Engineers re-explaining the same project context every session. Or the opposite failure: sessions hours long, degrading steadily, because clearing feels like losing progress. It isn't. The context was the cost, not the asset.
Reviewing and steering, not wholesale accepting
What it looks like: The engineer reads diffs as they land, interrupts early when the approach drifts, and course-corrects mid-task. Steering is cheap at minute two and expensive at minute twenty. The strong practitioner treats the agent like a capable colleague whose work gets reviewed in flight — not a vending machine whose output gets taken or thrown away whole.
Signal it's missing: Two patterns, both visible in sessions. Accept-then-patch: agent output merged untouched, followed by a trail of human fix-it commits. Or reject-and-retry: the same prompt re-rolled three times hoping for a better draw, with no feedback in between.
Building reusable skills and commands
What it looks like: The third time someone types the same setup paragraph — how we write migrations, how we structure a PR description — they turn it into a saved command or skill. Their tooling compounds. The team's strongest people have a personal library; the very strongest share it.
Signal it's missing: Ritual retyping. If you read someone's sessions and the same 200-word preamble opens every one, that's a skill file waiting to exist — and a sign nobody has shown them the mechanism.
Running sessions that don't feel like surveillance
The curriculum is the easy half. The failure mode that actually kills coaching programs is social: the moment session review feels like monitoring, it's over. Three rules keep it coaching.
Volunteer-first, always. Never pull up someone's session without their blessing. Open the program by asking for volunteers — and seed it by volunteering your own sessions first, including a messy one. The format that works: thirty minutes, biweekly, one person walks the group through a real session. What they asked, what the agent did, where they intervened. The discussion is the product.
Coach from strong examples, not weak ones. Review the session where the migration went well. Public dissection of struggling sessions teaches exactly one lesson — hide your sessions — and the audience learns more from "here's what good looks like in our codebase" than from a postmortem of someone's bad afternoon. Save struggle-sessions for private one-on-ones, when the person brings them.
Never wire it to performance review. Not subtly, not "as one input," not ever — and say so out loud, then keep the promise. The reason is practical, not just ethical: the moment session data touches evaluation, people optimize the metric instead of the work. They'll run plan mode performatively, pad sessions with practice-shaped noise, and route real work to channels you can't see. The data goes dead precisely because you weighted it. Coaching data is only honest while it's safe.
Running it without tooling
You can start this with no product at all. It's manual, but it works:
- Recruit two or three volunteers — ideally including one of your strongest practitioners and yourself.
- Capture sessions. Claude Code keeps transcripts locally; volunteers can export or screen-share a recent session. One caveat: transcripts purge after roughly 30 days, so "let's look at that great session from March" has a shelf life. Grab good examples when they happen.
- Hold the review. Thirty minutes, biweekly. One session, walked through by its owner. The group asks: where did the plan happen? Where did steering happen? What would you do differently?
- Track adoption coarsely. A spreadsheet — people as rows, the six practices as columns, a check when a practice shows up in someone's shared sessions. Crude, but it turns "how's the team doing with AI" into a picture.
- Write down what you find. When a review surfaces a technique worth spreading, capture it as a shared command or a one-paragraph play, not a memory.
The honest limitations: you only see what volunteers share, so the spreadsheet has survivor bias built in. Reading transcripts manually takes real time. And one biweekly session samples a tiny fraction of the team's actual reps. Manual coaching is a real program with a low ceiling — fine to start, frustrating to scale.
Where Accrete instruments the loop
This loop — capture sessions, spot practices, find the strong examples, track who's adopted what — is the thing Accrete automates. A small client on each developer's machine parses Claude Code transcripts into a durable database (outliving the 30-day purge), classifies the practice signals in every session, and builds the per-person × per-practice adoption matrix so you can see where the team plateaus and which session to pull up — with its owner's blessing — at the next review. Parsed session data only, one isolated database per company; the full boundary is on our privacy page, and the coaching workflow is laid out in coach your team.
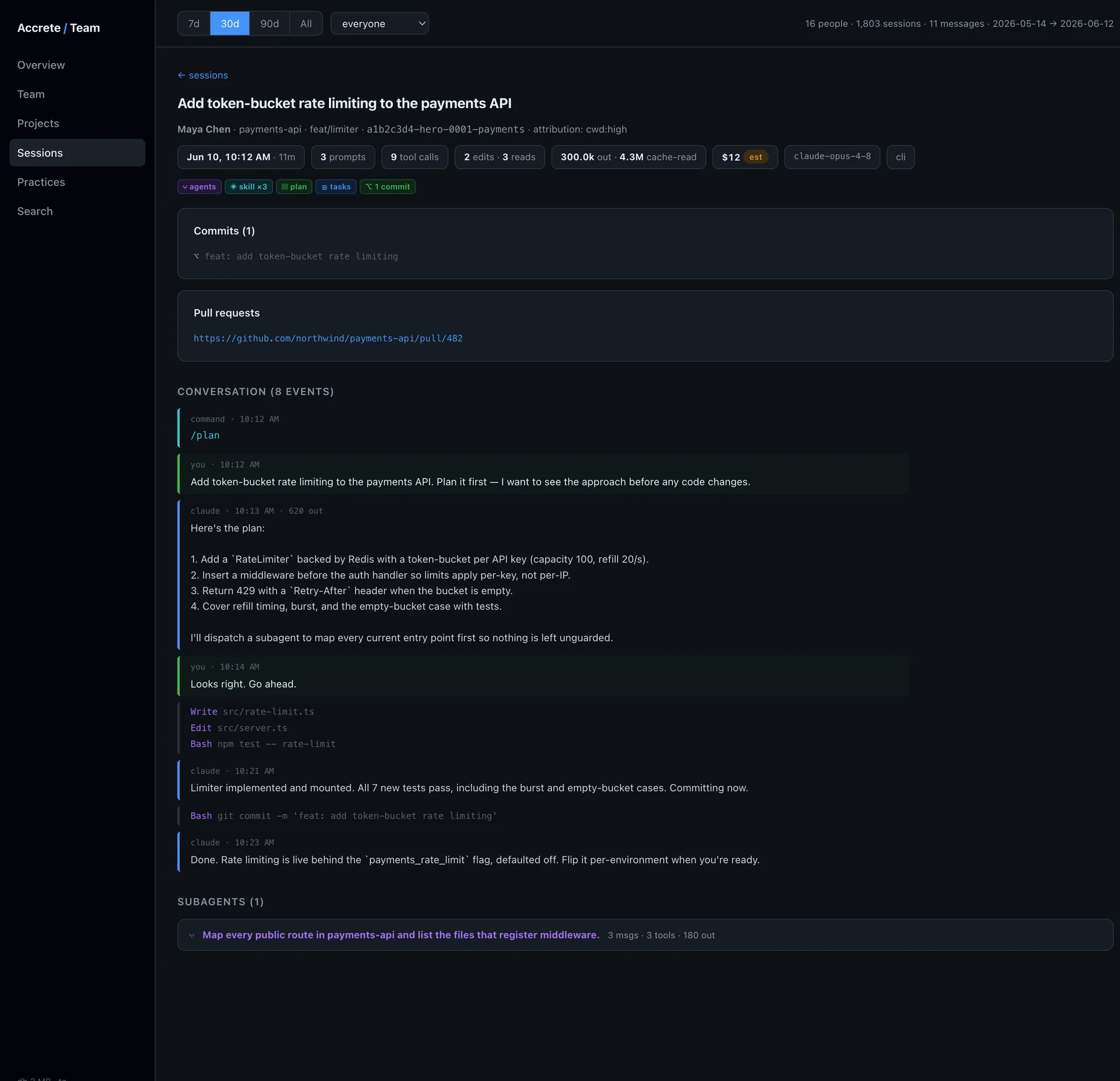
We're pre-launch and deliberately early. Join the early access list, or become a design partner and shape the practice catalog with the founder around what your team actually does. Either way: start the manual loop now. The reps are happening today, reviewed or not.